How do you create Multibranch Pipeline in Jenkins?
The Multibranch Pipeline project enables you to implement different Jenkins files for different branches of the same project. In a Multibranch Pipeline project, Jenkins automatically discovers, manages, and executes Pipelines for branches which contain a Jenkins file in source control.
When dealing with messaging systems there are a lot of options available from classical message brokers to simple libraries that handle the messaging logic without a central server. Almost all of them have some variances and each of them has a reason to exist. In this article we will be going to compare a few popular ones and very different ones, namely the message the socket and concurrency library ZeroMQ and the lightweight MQTT broker Mosquitto. Each of them has their own advantages and differences from the others and the client should choose one according to their needs.
MESSAGING PATTERNS
When talking about messaging systems we first have to understand the typical messaging patterns available. In some cases, the user wants to send messages from one program (producer) to another program (consumer) and in other cases the user might have multiple producers or multiple consumers or even multiple steps. Some of these patterns are so common that they have their own names.
PUBLISH-SUBSCRIBE
Publish-Subscribe is a messaging pattern where the user wants to send messages from a set of producers to different consumers. However, messages are not sent to the subscribers directly, but instead each message is published to a so-called topic and subscribers can subscribe to topics and recover only those messages.
COMPETING CONSUMERS
The Competing Consumer pattern is nothing but the user wants to use parallelized consumers to speed up the processing of their messages. In this state the user has one or multiple producers and a set of consumers, which are ready to read messages from the consumer. All of the consumers do the same job and could be mutually exchanged. When a consumer receives a message the message will be deleted and the other consumers won’t see it anymore. The next available consumer will get the next message and so on.
MESSAGING SYSTEMS
Knowing some of the different messaging patterns, let us have a look at some of the surviving messaging systems.
MOSQUITTO
Mosquitto is a lightweight MQTT broker supporting the publish-subscribe pattern. It does not support competing consumers or other protocols apart from MQTT. Mosquitto is accessible in the software repository of most Linux distributions.
If there is no pre-built package available or the user do not want to use them, the user can also install it from source code. The user has to make sure that he/she have the ares.h available on their system. Depending on the distribution this is included in a package called c-ares or libc-ares-dev.
If the user has installed mosquitto from their package manager, the user should be able to start it with the standard daemon manager (systemd, SysVinit). Otherwise, it’s as simple as calling mosquitto to start the server and it will greet you with:
1509264671: mosquitto version 1.4.14 (build date 2017-10-29 08:06:39+0000) starting
1509264671: Using default config.
1509264671: Opening ipv4 listen socket on port 1883.
1509264671: Opening ipv6 listen socket on port 1883.
If the user has executed make && and install during compilation of mosquitto, libmosquitto.so.1 and will be installed to /usr/local/lib/libmosquitto.so.1. The user can now try to run the client programs mosquitto_sub or mosquitto_pub, this might give the error:
mosquitto_sub: error while loading shared libraries: libmosquitto.so.1: cannot open shared object file: No such file or directory
For communication with Mosquitto the user should be able to use any MQTT client library. There are command line clients available from mosquitto called mosquitto_pub and mosquitto_sub.
ZEROMQ
What if the user wants to support more messaging patterns than Mosquitto, but still want to have a lightweight solution? Then ZeroMQ might be the best option to go. Unlike all other solutions in this series, ZeroMQ is not a central server, but just a library which the user can use in the client programs. It looks similar to standard networking from a user’s perspective, but in the background it handles the overhead of network communication.
ZeroMQ does support both the publish-subscribe and the competing consumers pattern, but since it does not have a central server, the user will have to write a simple server in ZeroMQ if the user wants to have many connections.
PUBLISH-SUBSCRIBE
ZeroMQ is simple to install, because it is just a library. For Python, we can get it from pip with:
pip install zmq
The publish-subscribe pattern works quite alike to MQTT. The only difference is that with ZeroMQ the user cannot subscribe to topics, but instead the user subscribes to a message prefix.
While some companies still use manual coding and pre-built adapters to provide access to systems, this often poses potential security issues. Application access through these methods allow unsecured and uncertified custom code, which could lead to a serious security flaw in the user’s network infrastructure. Identity and authentication, Single Sign-On (SSO) and secure API access are what outbreaks the developers. There enter SAML and OAuth. But as an enterprise organization, which one should you use? Which one is better?
In many cases, the answer to both of these questions may depend on the application and access needed. The bottom line is that both provide some comparable functionalities but they solve different problems. So, explore this article and look at some basic definitions of SAML and OAuth and their major differences.
SAML
The Security Assertion Mark-up Language (SAML), is an open standard that allows security authorizations to be shared by multiple computers across a network. It describes a framework that allows one computer to perform some security functions on behalf of one or more computers.
OAUTH
OAuth is an authorization protocol, in other words, a set of rules that allows a third-party website or application to access the user’s data without the user needing to share login credentials.
OAuth’s open-source protocol enables the users to share their data and resources stored on one site with another site under a secure authorization scheme based on a token-based authorization mechanism.
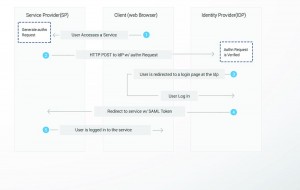
THE SAML WORKFLOW
An end user clicks on the “Login” button on a file sharing service. The file sharing service is the Service Provider, and the end user is the Client.
To authenticate the user, it constructs a SAML Authentication Request, signs and optionally encrypts it, and sends it directly to the IdP.
The Service Provider redirects the Client’s browser to the IdP for authentication.
The IdP validates the received SAML Authentication Request and if valid, presents a login form for the end user to enter his username and password.
Once the Client has successfully logged in, the IdP generates a SAML, which also includes the user identity and sends it directly to the Service Provider.
The IdP redirects the Client back to the Service Provider.
The Service Provider verifies the SAML Assertion, extracts the user identity from it, assigns correct permissions for the Client and then logs the client in to the service.
SAML 2.0 FLOW
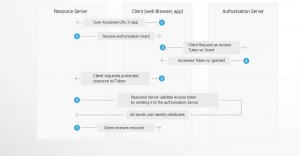
THE OAUTH WORKFLOW
OAuth does not assume that the Client is a web browser.
The example workflow proceeds as follows:
An end user clicks on the “Login” button on a file sharing service. The file sharing service is the Resource Server, and the end user is the Client.
The Resource Server presents the Client with an Authorisation Grant, and redirects the Client to the Authorisation Server.
The Client requests an Access Token from the Authorisation Server using the Authorisation Grant Code.
The Client logs in to the Authorisation Server, and if the code is valid, the Client gets an Access Token that can be used to request a protected resource from the Resource Server.
After receiving a request for a protected resource with an accompanying Access Token, the Resource Server verifies the validity of the token directly with the Authorisation Server.
If the token is valid, the Authorisation Server sends information about the Client to the Resource Server.
OAUTH 2.0 FLOW THE OTHER DIFFERENCES
TOKEN OR MESSAGE FORMAT
SAML deals with XML as the data construct or token format.
OAuth tokens can be binary.
TRANSPORT
SAML has Bindings that use HTTP such as HTTP POST Binding, HTTP REDIRECT Binding etc.
But there is no restriction on the transport format. The client can use SOAP or JMS or any transport they want to send SAML tokens or messages.
OAuth uses HTTP exclusively.
SCOPE
Even though SAML was designed to be applicable openly, it is typically used in Enterprise SSO set-ups:
Within an enterprise or
Enterprise to partner or
Enterprise to cloud scenarios.
OAuth has been designed for the use with applications on the internet, primarily for delegated authorization of internet resources. OAuth is designed for Internet Scale.
AWS Greengrass is a software that extends AWS cloud capabilities to local devices, making it possible to collect and analyze data closer to the source of information, while also steadily communicating with each other on local networks. More precisely, developers who use AWS Greengrass can author server less code in the cloud and conveniently deploy it to devices for local execution of applications.
When Andy Jassy announced the release of AWS Greengrass in Limited Preview back in November at AWS reinvent 2016, the show floor was vibrant for hours. AWS Greengrass promises to power up what “the Edge” by allowing connected devices to run local compute, messaging, data caching, and synch capabilities securely, even when they are not connected to the Internet.
And while connectivity stands at the core of IoT, if the user is developing or deploying connected devices the user cannot always count on a steady connection. AWS Greengrass also lets one device act as a hub for others, so they can save energy by keeping data connections with a local intranet.
The latest announcement of general availability for AWS Greengrass is a big deal for IoT developers. It is a one of the important new component in the Cloud toolkit that powers IoT, and gives us few things to consider.
KEY TAKEOUT’S FROM AWS GREENGRASS ANNOUNCEMENT SOFTWARE SKILLS ARE NOW PORTABLE TO IOT
Greengrass moving more of what software developers do to the edge of the network is a major inflection point.
The enormous software developer community is already moving into IoT, and tools like AWS Greengrass will help to rule the space over time. Their familiarity with programming in languages such as Python and writing lambdas to process streaming data in-flow now becomes applicable on the other side of the “choke point.”
CONNECTIVITY IS MORE IMPORTANT
When it comes to connectivity, IoT developers need solutions that are simple, reliable, and flexible.
Existing product offerings rarely deliver on all three, and often burden projects with significant commercial and technical constraints even during development and testing. Signing complicated contracts in the prototype stage, when there is no guarantee that devices will even work as designed, can still require a years-long upfront commitment.
EFFICIENCY MATTERS
The communication between a device and the cloud comes with the burden of retransmitting repetitive, undifferentiated data related to security, encryption, and packet headers.
A significant portion of IoT cellular opex is 25% to as much as 75% or more in many cases it is related directly to this overhead or “connectivity tax.”
Both are highly preferable for the performance and a cost perspective to transmit only the meaningful data.
THE TOTAL PACKAGE FOR IOT
Device-based environments such as AWS Greengrass promise a new, easier IoT featuring:
Familiar development tools.
Pre-processing on constrained devices.
Decreased cellular data connectivity (or newer variants such as RPMA, NB-IoT, CAT-M).
A flexible, take-what-you-need, pay-as-you-go fee structure.
Augmented reality and virtual reality are the two ways that tech can change the way you look at the world. The terms can be puzzling. Sometimes many people think AR and VR both are same thing. Augmented Reality and Virtual Reality are increasingly being used in technology, so knowing the difference is important. Explore this article and know the major differences between AR and VR.
AUGMENTED REALITY
Augmented reality is defined as “an improved version of reality created by using technology to add digital information on an image of something.”
AR is used in smartphones applications and tablets. AR apps uses phone’s camera to show the user a view of the real world in front of them, then place a layer of information, including text or images, on top of that view.
Applications can use AR for fun, such as the game Pokémon GO, or for specific information, such as the Layar app.
The Layar app can show the user an interesting information about places the user visit, using augmented reality. Open the app when you are visiting a site and read the information that appears in a layer over your view.
The user can also find money machines, can also view real estate for sale, find restaurants, and much more using the AR feature of the app. The user can even discover new sites they did not know that they are existed.
VIRTUAL REALITY
Virtual Reality is defined as “the use of computer technology to create a replicated environment.”
When the user views VR, user is viewing a completely different reality than the one in front of everyone.
Virtual reality may be artificial, such as an animated scene, or an actual place that has been photographed and included in a virtual reality application.
With virtual reality, the user can move around and can look in every direction — up, down, slanting and behind, as if the person is physically there.
The user can view virtual reality through a special VR viewer, such as the Oculus Rift. Other virtual reality viewers use their phone and VR apps, such as Google Cardboard or Daydream View.
THE VERDICT
As technology progresses and we continue to add more to the virtual experience, we are probably going to see a lot more in over the next few years. Who knows where it’s going to go in next few years? Maybe a fully simulated future is not as far off as we thought.
Kafka’s growth is exploding. More than one-third of all Fortune 500 companies are using Kafka. Kafka is used for real-time streams of data, to collect big data, or to do real time analysis. Kafka is used with in-memory micro services to provide stability and it can be used to feed events to CEP (complex event streaming systems) and IoT/IFTTT-style automation systems. So, explore this article and know what Kafka is and why it is important.
KAFKA
Kafka is a distributed streaming platform that is used to publish and subscribe to streams of records. Kafka is used for fault tolerant storage. Kafka duplicates topic log partitions to multiple servers. Kafka is designed to allow the users apps to process records as they occur. Kafka is fast and uses IO proficiently by batching and compressing records. Kafka is also used for decoupling data streams. It is used to stream data into data lakes, applications, and real-time stream analytics systems.
WHY KAFKA?
Kafka is usually used in real-time streaming data architectures to deliver real-time analytics. Kafka is also fast, scalable, sturdy, and fault-tolerant publish-subscribe messaging system. Kafka is used in use cases where JMS, RabbitMQ, and AMQP may not even be considered due to capacity and responsiveness. Kafka has higher throughput, reliability, and duplication characteristics, which makes it applicable for things such as tracking service calls or tracking IoT sensor data where a traditional MOM might not be considered.
Kafka can also work with Flume/Flafka, Spark Streaming, Storm, HBase, Flink, and Spark for real-time ingesting, analysis and processing of stream data. Kafka traders support huge message streams for low-latency follow-up analysis in Hadoop or Spark. Also, Kafka Streaming can be used for real-time analytics.
WHY KAFKA SO POPULAR?
Kafka has operational ease. Kafka is used to set up and use, and it is easy to figure out how Kafka works. However, the main reason Kafka is very popular is because of its excellent performance. It is stable, provides reliable durability, has a flexible publish-subscribe/queue that scales well with N-number of consumer groups, has robust replication, provides producers with tuneable consistency guarantees. In addition, Kafka works well with systems that have data streams to develop and enables those systems to aggregate, alter, and load into other stores. But none of those characteristics would matter if Kafka was slow. The most important reason Kafka is popular is Kafka’s unique performance.
KAFKA USE CASES
Kafka is used for stream processing, website activity tracking, metrics collection, and monitoring, log aggregation, real-time analytics, ingesting data into Hadoop, CQRS, replay messages, error recovery, and guaranteed distributed commit log for in-memory computing.
KAFKA IS FAST
Kafka relies heavily on the OS kernel to move data around quickly. It relies on the principals of zero copy. Kafka enables the user to batch data records into portions. These batches of data can be seen end-to-end from producer to file system to the consumer. Batching allows for more efficient data compression and reduces I/O latency. Kafka writes to the immutable commit log to the disk sequential, thus evading random disk access and slow disk seeking. It shards a topic log into hundreds of partitions to thousands of servers. This sharding allows Kafka to handle huge load.
IS USING KAFKA A GOOD IDEA?
The answer will always depend on what the user use case is. Kafka fits a class of problems that handles a lot of web-scale organizations and enterprises, but just as the traditional message broker is not a one size which fits to all, neither is Kafka. If you are looking to build a set of resilient data services and applications, Kafka can function as the source of truth by collecting and keeping all of the “facts” or “events” for a system.
In the end, the user has to consider the trade-offs and disadvantages. If you think you can profit from having multiple publish/subscribe and queueing tools, it might be worth considering.
By adding logback.xml file to the application we can override the default logging configuration by providing the Spring Boot. This file isplaced in the classpath (src/main/resources) of the application for Spring Boot to pick the custom configuration.
What does @EnableAutoConfiguration do? What about @SpringBootApplication?
@EnableAutoConfiguration annotation on a Spring Java configuration class
– Causes Spring Boot to automatically creates beans you need.
– Usually based on classpath contents, can easily override.
@Configuration
@EnableAutoConfiguration
public class MyAppConfig {
public static void main(String[] args) {
SpringApplication.run(MyAppConfig.class, args);
}
}
@SpringBootApplication was available from Spring Boot 1.2
It is very common to use @EnableAutoConfiguration, @Configuration, and @ComponentScan together.
@Configuration
@ComponentScan
@EnableAutoConfiguration
public class MyAppConfig {
…
}
With @SpringBootApplication annotation
@SpringBootApplication
public class MyAppConfig {
…
}
What are the advantages and disadvantages of using Spring Boot?
Advantages:
It is very easy to develop Spring Based applications with Java or Groovy.
It reduces a lot of development time and increases productivity.
It avoids writing of boilerplate Code, Annotations and XML Configuration.
It is very easy to integrate Spring Boot Application with its Spring Ecosystem like Spring JDBC, Spring ORM, Spring Data, Spring Security etc.
It follows “Opinionated Defaults Configuration” Approach to reduce Developer effort
It provides Embedded HTTP servers like Tomcat, Jetty etc. to develop and test our web applications very easily.
It provides CLI (Command Line Interface) tool to develop and test Spring Boot (Java or Groovy) Applications from command prompt very easily and quickly.
It provides lots of plugins to develop and test Spring Boot Applications and it uses Build Tools like Maven and Gradle
It provides lots of plugins to work with embedded and in-memory Databases very easily.
Disadvantages:
It is very tough and time consuming process to convert existing or legacy Spring Framework projects into Spring Boot Applications. It is applicable only for brand new/Greenfield Spring Projects.